今天的主題是學習 Web 爬蟲 (Web Scraping) ,它是一種從網站上自動擷取資料的技術。會使用到 Pyhon 中的 requests 和 BeautifulSoup 套件來進行簡單的網頁爬取。這個實作將分為幾個步驟,包括設置環境、發送請求、解析網頁、提取數據,並將數據整理輸出。
首先,需要安裝兩個 Python 爬蟲的套件:requests 和 BeautifulSoup,這兩個工具分別用來發送 HTTP 請求並解析 HTML 網頁內容。
要在命令提示字元中運行以下命令:
pip install requests
pip install beautifulsoup4
pip install beautifulsoup4 requests
接下來,使用 requests 庫向發送 HTTP 請求,並將網頁的 HTML 內容儲存在 response 變數中,就可以用response.text取得完整的 HTML 文本。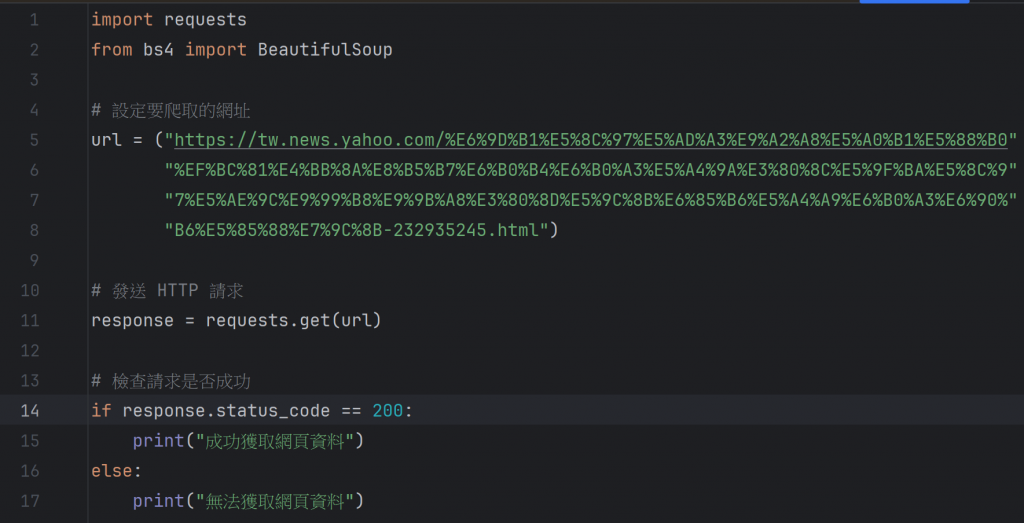
再用 BeautifulSoup 將 HTML 資料解析成 Python 物件,這樣可以更方便地提取特定的標籤或內容。
例如:提取新聞的標題和內文。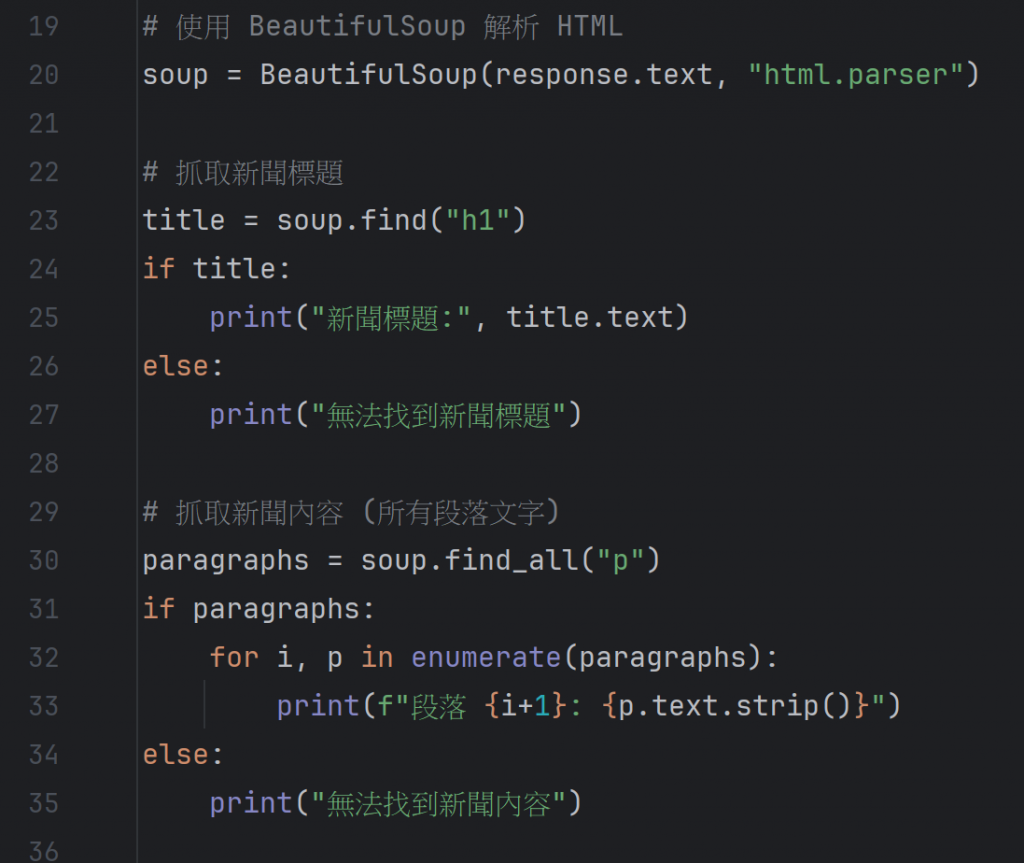
這裡使用 soup.find("h1") 抓取<h1>標籤內的新聞標題,並使用 soup.find_all("p") 抓取頁面內所有<p> 標籤內的段落內容。
最後,將抓取到的資料整理並印出或儲存在本地文件中。這有助於將資料轉換成有用的資訊,例如生成報告或進行進一步分析。
這段程式會提取前幾段的內容作為新聞摘要,這樣可以讓結果更加簡潔。
如果想將資料儲存成文件: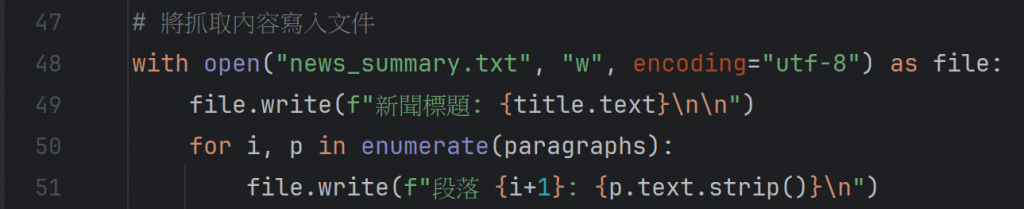
輸出結果:
新聞標題: 東北季風報到!今起水氣多,基北宜陸陸雨
新聞內容:
根據氣象局的最新預報,今天(7日)開始,東北季風影響明顯,水氣逐漸增多。預計北部及東部地區將出現短暫陣雨,特別是在基隆和宜蘭一帶,降雨的機率較高。氣象局提醒民眾出門時,記得攜帶雨具,以備不時之需。
氣溫方面,白天的高溫大約在22至25度之間,夜間氣溫則會降到18度,民眾需適時增添衣物,以免感冒。
這股東北季風預計將持續影響數天,週末天氣會有所好轉,但仍建議計畫外出的民眾隨時關注氣象預報,保持靈活應變的心態。
今天進行了簡單的 Web 爬蟲操作,安裝套件到發送請求,並解析 HTML 文件,最後將數據存儲成文字檔案,這些都是 Web 爬蟲的基本流程。透過這個實作我不僅能夠學會如何從網頁中提取特定資訊,以及如何操作和處理這些數據。

